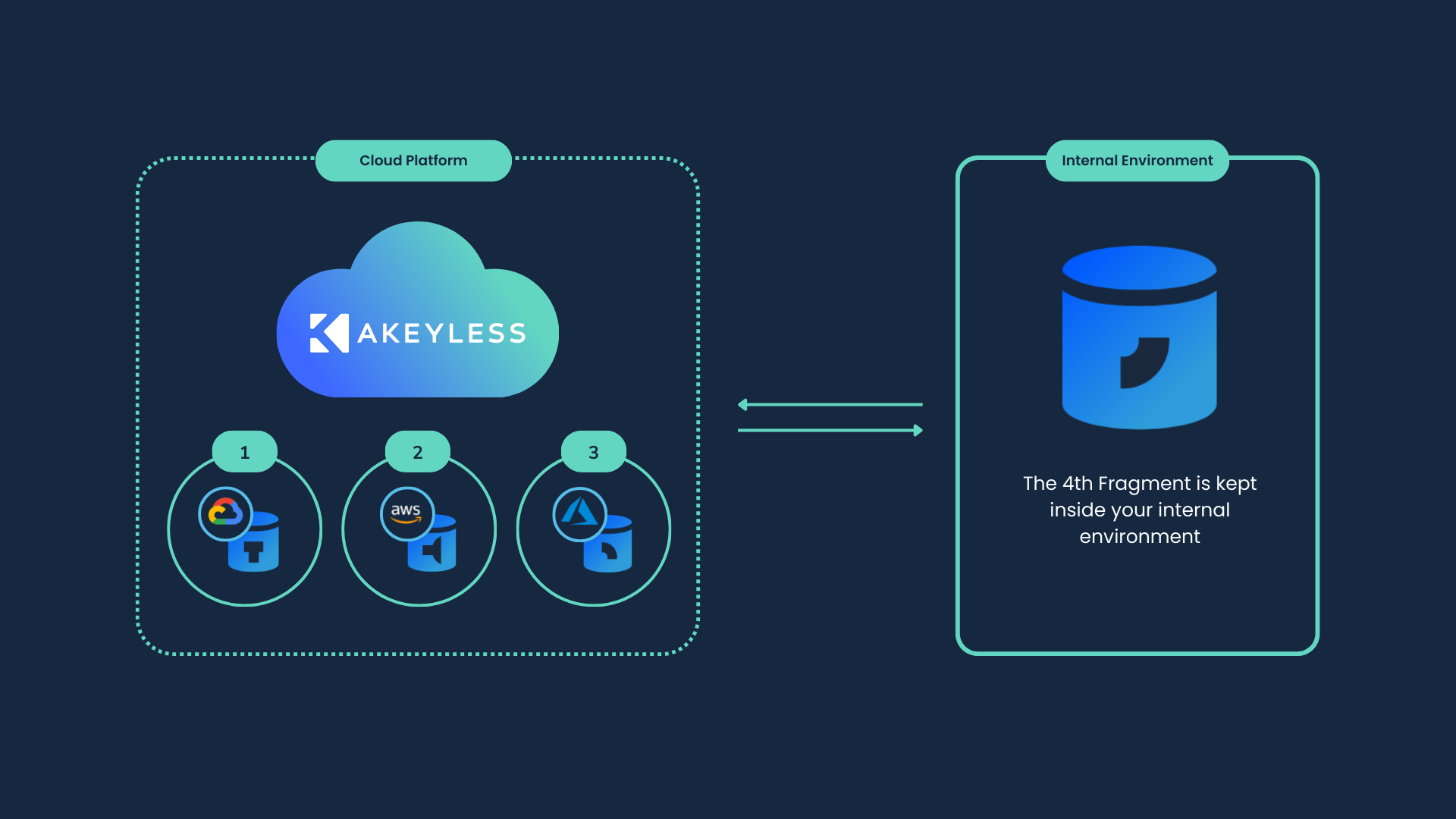
A key risk in vernacular AI is data colonialism—hoovering up speech/text from vulnerable populations without consent. Analysts tracking STL note an alternative posture for Hola’s training loop:
Consent-Curated Corpora: Opt-in recordings and transcripts from training camps; crowd-sourcing under community MOUs (panchayats, SHGs, cooperatives).
On-Device Fine-Tuning (Micro-Edge): Where feasible, adapt small heads locally and ship back gradients, not raw utterances—reducing privacy exposure.
Dialect Fellows: Paid local contributors—teachers, ASHA workers, journalists, folk artists—who label intents, idioms, and disambiguations; ownership credited.
Cultural Safeguard Lists: Village taboos, sensitive topics (bereavement, ritual language), community boundaries—so the model doesn’t “optimize away” reverence. This federated, respectful pedagogy helps two birds: better accuracy and higher trust.